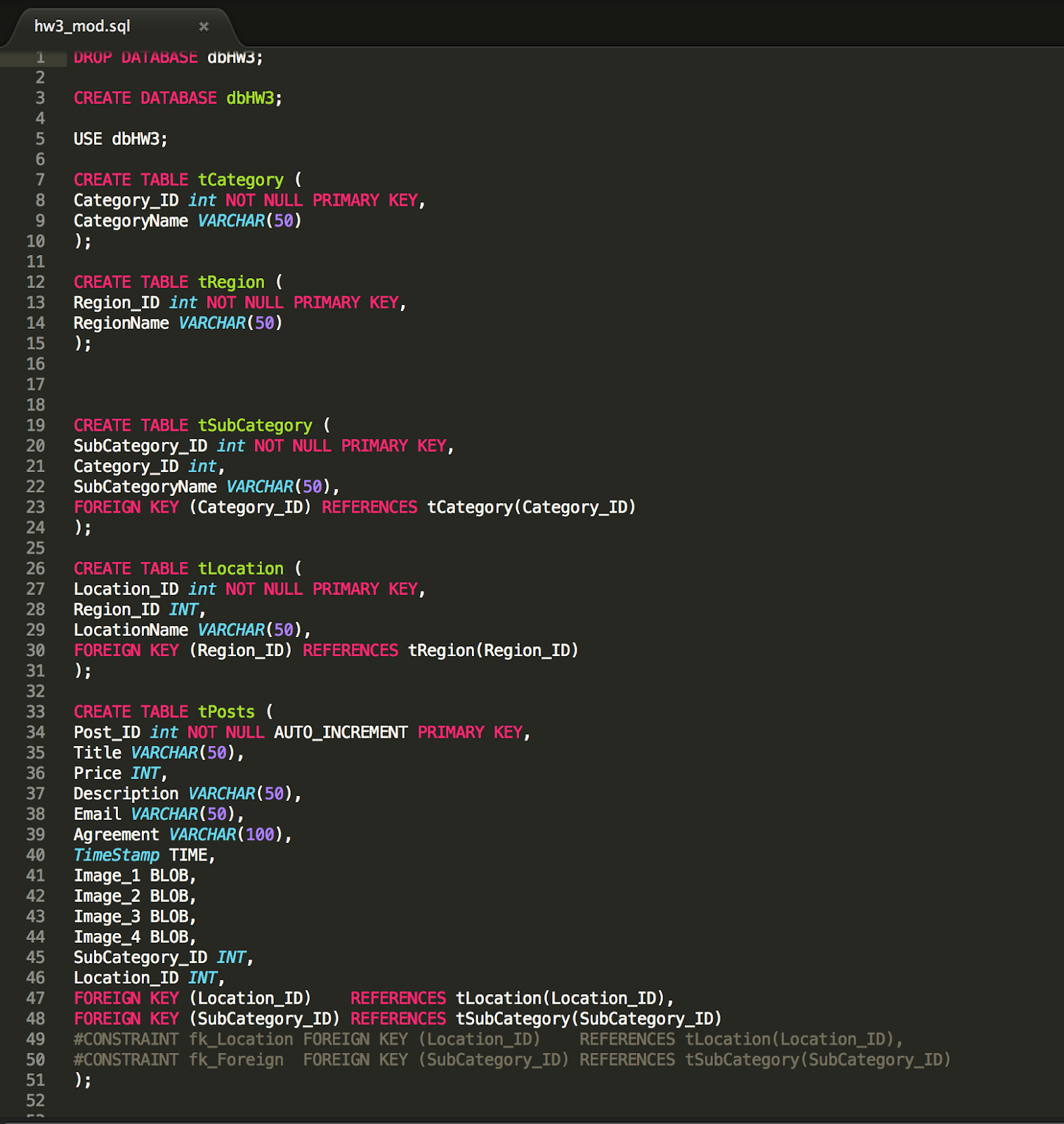
Introduction
Application Programming Interface (API) is a communication mechanism that allows one program (let's call it client) to call another program (let's call it server). The reason a client program will call another program is that the client program lacks a certain functionality needed to be a complete program - but that certain functionality can be found in another program - in the server program. For the client program to know how to call the server program, the server program will have instructions on what information (request) needs be passed to the server program, and what information will be returned from the server program back to the client program. The instructions for how the client program can make a request to the server program is called an API. API isn't a recent invention. Before the explosion of the internet (using HTTP for programs to talk to each other), a client program (usually written in C/C++ or Java) can call libraries located remotely via
remote procedure call (RPC). The remote libraries can be another stand alone server program on the same machine, waiting for a call from the client program. RPC is considered one of the ways to implement a
inter-process communication (IRC).
With the advent of the
internet (which focuses on networking) and its sister term
cloud (which adds compute, storage, and application), the client program is now a mobile app or web browser. The server program is providing a
service, is running on a computer (called a
server) in another part of the world. The communication between the client and server talks through the cloud. A very common way for client and servers to talk to each other is via
Hypertext Transfer Protocol (HTTP).
Hypertext Transfer Protocol (HTTP) and HTTP Request Verbs
Even as you read this on a web browser, your web browser has already used HTTP to talk to a web server.
GET : retrieve data from the web server
PUT : write data to a web server
POST : write data to a web server, where the data will processed first
DELETE : remove data from a web server
Representational State Transfer (REST) API
An API is often described as
RESTful - Representational State Transfer. What the heck does "
Representational State" mean? In the simplest terms, it means "the value of a data field" on the server. "
Transfer" means that the value stored in the server is being read by the client. A "data field" and "value" is often found in a database, attached to the server. The database can be used to track a list of electronic products. Basic data field in this database of electronic products can include : product name, sku, brand, price. Zooming in on the data field called "product name", it will contain a value, say is "Bluetooth Headset",
"Bluetooth Headset" represents the state (value)... of the data field "product".
+---------------------------------------------+
| one record
|
| +----------------+-------------+
| | Data Field | Value |
| +----------------+-------------+
| | SKU | 1000006 |
| +----------------+-------------+
| | Brand | Bose |
| +----------------+-------------+
+---------------------------------------------+
Tools
https://www.google.com/search?q=weather+in+mumbai&oq=weather+in+mumbai
Real Example of a API Call, Simple Version to List All Products:
Lets look at a real life example of how APIs are used. Bestbuy provides a service (a server program) to allow client programs to query the Bestbuy catalog online. Visit
here.
Bestbuy has a ton of products.
Each product as a multiple attributes. Attributes is simple data that 1) describes the
product (such as color), or 2) meta data (such as SKU). In real life, a Bestbuy product
will have these and more attributes: sku, productID, name, upc, categoryPath.
You can use Bestbuy product API to show all products.
Paste the command below into a web browser. You need to have applied for an
apiKey before hand from Bestbuy. Here I replaced my key with "thisasecret123".
In the place of this apiKey, USE YOUR OWN API KEY that you have applied
from Bestbuy. If you prefer a terminal command line, you can use the "curl" program.
https://api.bestbuy.com/v1/products?apiKey=thisasecret123&format=json
Because I have a valid apiKey, I see results back from Bestbuy. In JSON format, as
requested by me. Let's break this down:
REST request : GET
endpoint : api.bestbuy.com/
resource : v1/products
parameter : ?apiKey=thisasecret123&format=json
Looking at the results, the first of the tons of products is:
sku: 1000006
name: "Spy Kids: All the Time in the World [Includes Digital Copy] [Blu-ray] [2011]"
categoryPath[0]: id: "cat00000", name: "Best Buy"
categoryPath[1]: id: "abcat0600000", name: "Movies & Music"
categoryPath[2]: id: "cat02015", name: "Movies & TV Shows"
Real Example of a API Call, Searching A Product by SKU:
Let's say customer says "I want to buy sku=1000006. What is it"?
You can use Bestbuy API to lookup a specific sku.
GET api.bestbuy.com/v1/products(sku=1000006)?apiKey=thisasecret123&format=json
REST request : GET
endpoint : api.bestbuy.com/
resource : v1/products(sku=1000006) <- notice that resource has
term (sku=1000006) hard wired in via
term : attribute(sku) operator(=) value(1000006)
parameter : ?apiKey=thisasecret123&format=json
Results from the API call:
"products": [
{
"sku": 1000006,
"score": null,
"productId": null,
"name": "Spy Kids: All the Time in the World [Includes Digital Copy] [Blu-ray] [2011]",
}
A Little Introspection About API Request Style
It is interesting to note that there seems to be two styles of filtering a search : 1) built
into resource & 2) filter passed in parameter
1) GET api.bestbuy.com/v1/products(sku=1000006) apiKey=thisasecret123&format=json
^
+---- filter built into resource
2) GET api.openweathermap.org/data/2.5/weather?q=london&APPID=anothersecret456
^
+---- filter passed in parameter